
A few Great Resources
for Delivering Solutions
Video References
"I've never seen this information shared more beautifully. Myke has taken the time to dive deeply into so many topics and he presents it so thoughtfully."

Tools & Frameworks
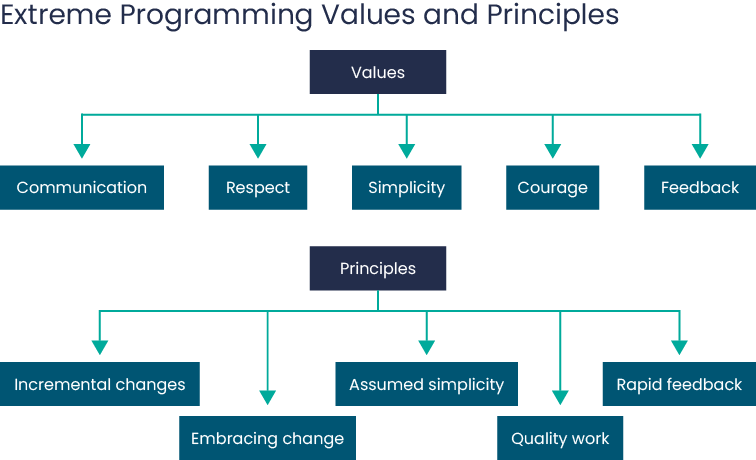
Source: Neashore-it.eu
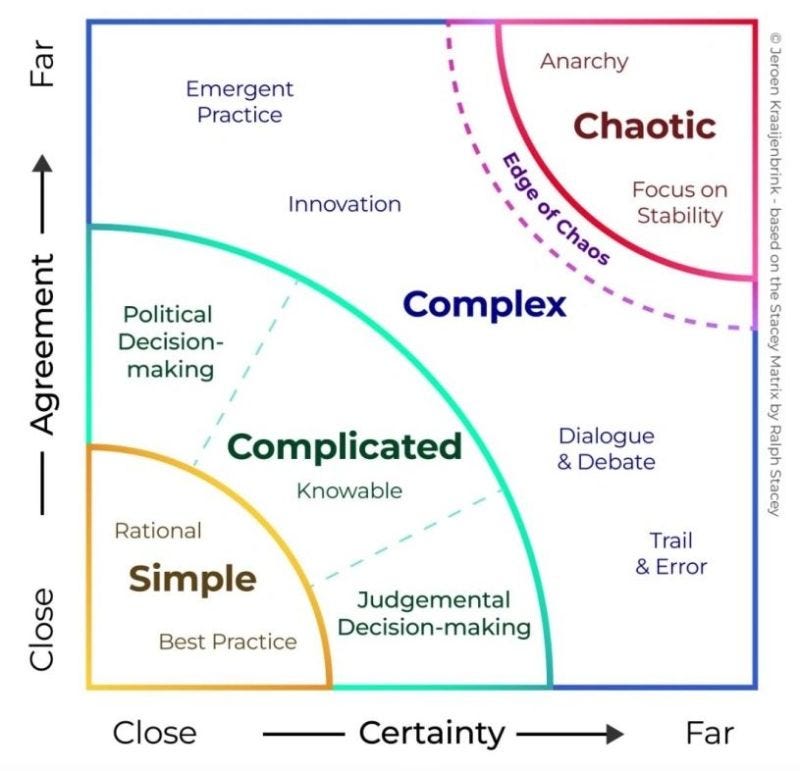
Source: juanfernandopacheco.medium.com
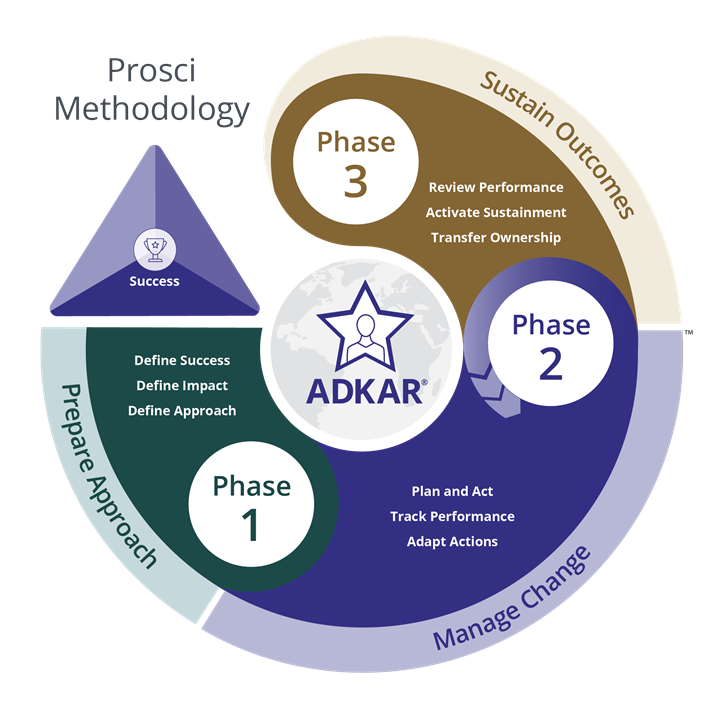
Source: www.prosci.com

Source: www.prosci.com
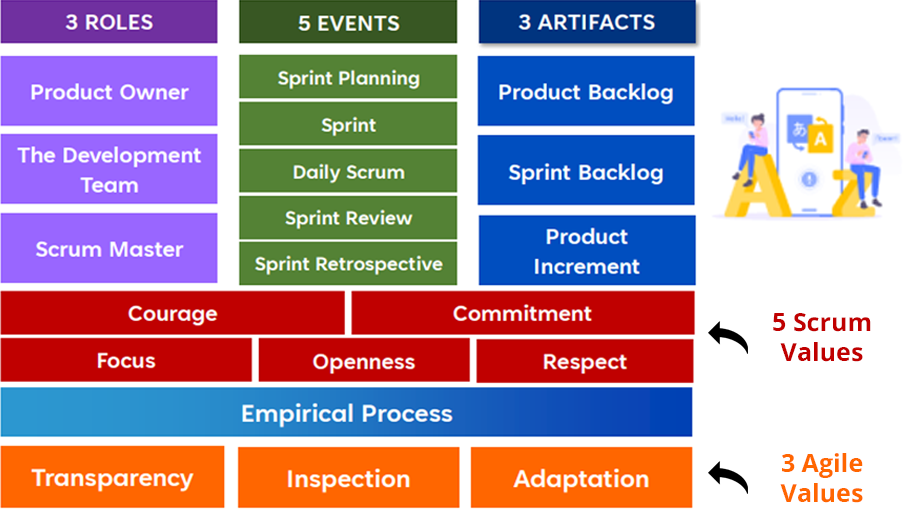

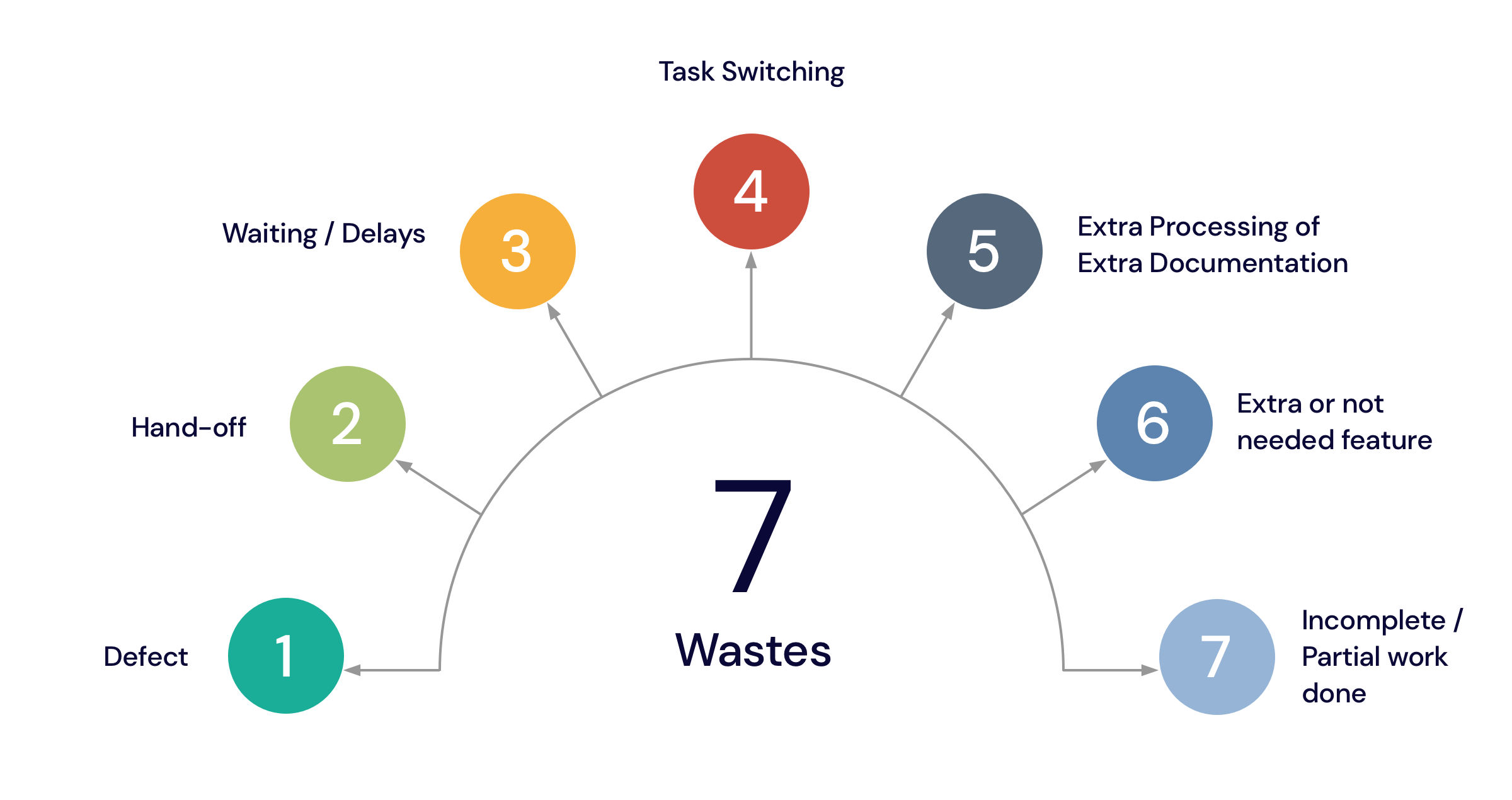
There are at least seven typical types of waste found in software development:
Defects. Each time a defect is found, it creates failure demand, i.e. the work you have to do now because something wasn’t done properly in the past. For example, most work-facing support teams can be classified as failure demand. This can include failure to create appropriate user documentation, or failure to properly code a feature.
Handoffs. There is always a level of tacit or implied knowledge that exists, as it’s impossible to capture every decision or every little piece of information that might be needed. It was estimated that each time you hand off a piece of work to someone else, as much as 50% of that tacit knowledge is lost. Excessive handoffs can sabotage the way workflows through the process, creating delays, relearning, task switching, and other waste.
Delay. Actually, delays can be caused by many different factors. For example, if the organization has functional work structures, work must pass through multiple teams in order to be completed, which may lead to setbacks in decision-making or delays in approvals.
Task switching. Every time you put one task aside to start another, you lose time to refocus and switch the context. This is particularly acute for complex tasks. Without even realizing it, stopping and returning to tasks will lead to a lot of interruptions and excessive work.
Relearning. If chaos prevails in your documentation, you can’t recall what was already learned, or expertise is available to you via your colleagues but you don’t make use of it, you’ll experience relearning. Unlike learning, relearning decreases your capability to deliver quickly or sustainably.
Extra features. If the customer doesn’t need a feature, it’s a waste. Creating extra features leads to an unnecessarily complex codebase that’s difficult to maintain and build upon. This buildup is one of the reasons big businesses often deliver more slowly than startups.
Partially done work. This includes unused designs, specifications, unverified code, tests, shelved work, etc. This usually occurs when you plan too early, multitask or change priorities frequently.
Source: railsware.com
“The tools Myke gave us and the thought-provoking discussions he opened up helped us exceed what we were set to do. As a result, our team earned an award for our Q4 delivery work.”

Process References
Source: bytebytego.com
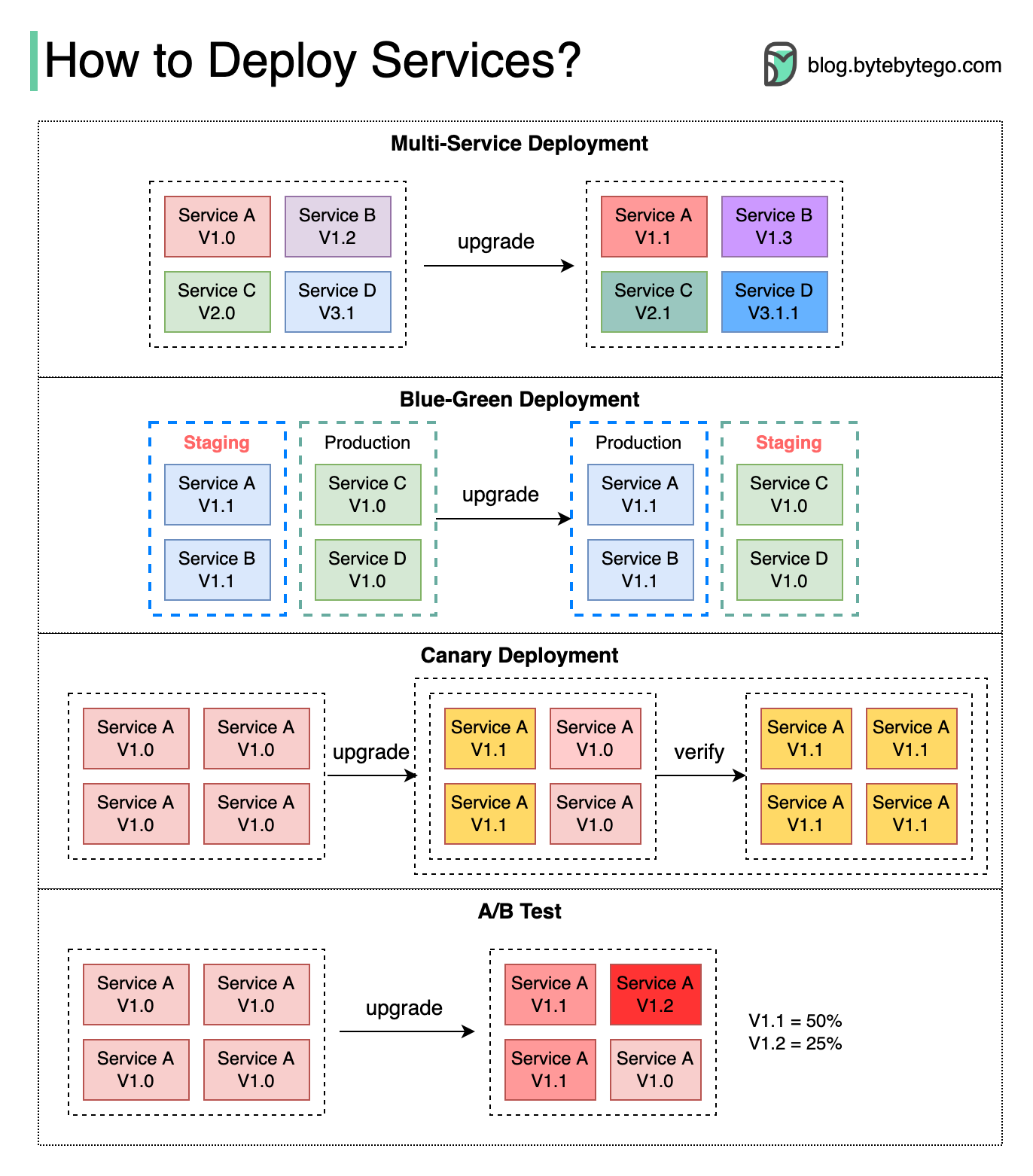
Deploying or upgrading services is risky. In this post, we explore risk mitigation strategies.
Multi-Service Deployment
In this model, we deploy new changes to multiple services simultaneously. This approach is easy to implement. But since all the services are upgraded at the same time, it is hard to manage and test dependencies. It’s also hard to rollback safely.
Blue-Green Deployment
With blue-green deployment, we have two identical environments: one is staging (blue) and the other is production (green). The staging environment is one version ahead of production. Once testing is done in the staging environment, user traffic is switched to the staging environment, and the staging becomes the production. This deployment strategy is simple to perform rollback, but having two identical production quality environments could be expensive.
Canary Deployment
A canary deployment upgrades services gradually, each time to a subset of users. It is cheaper than blue-green deployment and easy to perform rollback. However, since there is no staging environment, we have to test on production. This process is more complicated because we need to monitor the canary while gradually migrating more and more users away from the old version.
A/B Test
In the A/B test, different versions of services run in production simultaneously. Each version runs an “experiment” for a subset of users. A/B test is a cheap method to test new features in production. We need to control the deployment process in case some features are pushed to users by accident.
Source: bytebytego.com
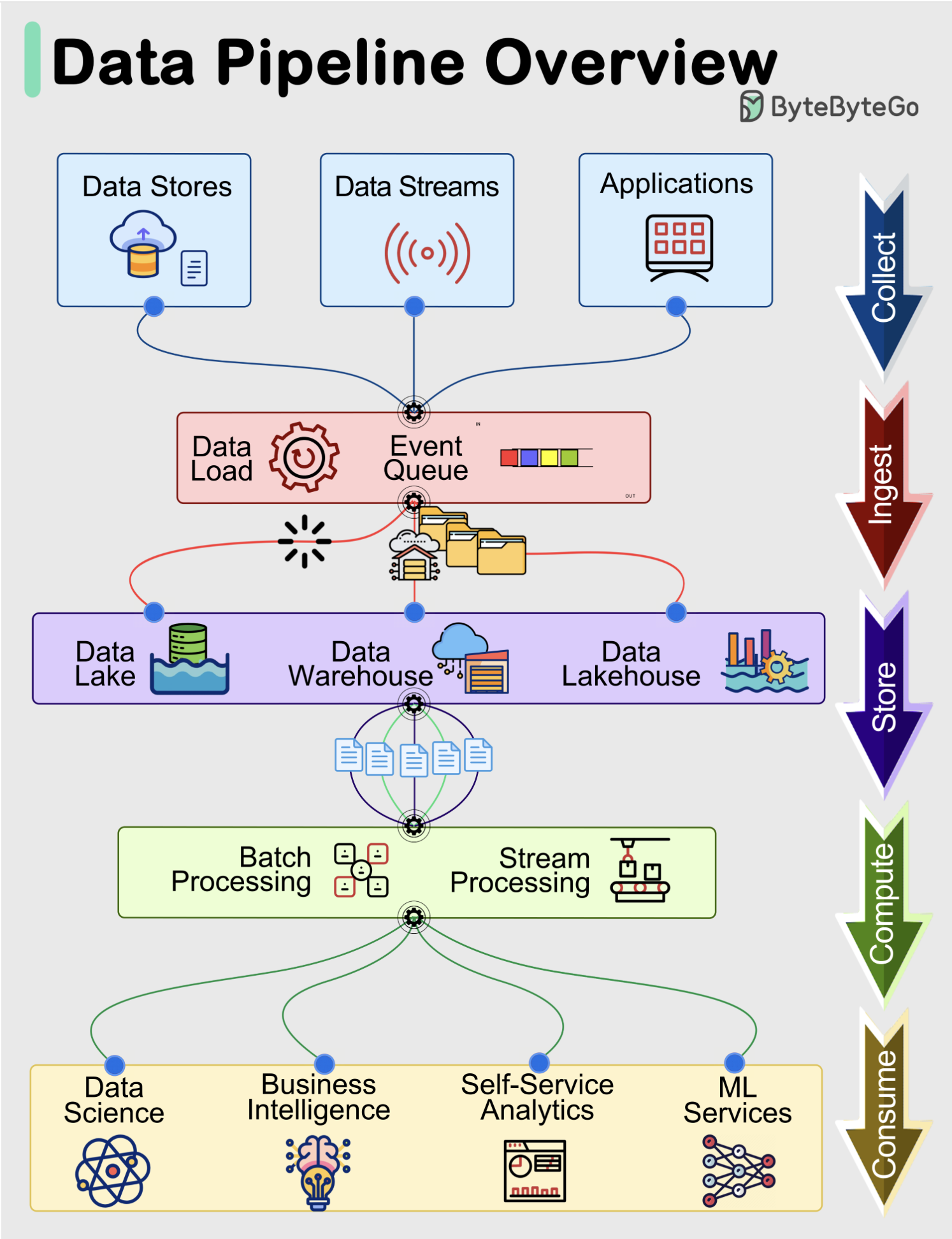
Data pipelines are a fundamental component of managing and processing data efficiently within modern systems. These pipelines typically encompass 5 predominant phases: Collect, Ingest, Store, Compute, and Consume.
Collect:
Data is acquired from data stores, data streams, and applications, sourced remotely from devices, applications, or business systems.
Ingest:
During the ingestion process, data is loaded into systems and organized within event queues.
Store:
Post ingestion, organized data is stored in data warehouses, data lakes, and data lakehouses, along with various systems like databases, ensuring post-ingestion storage.
Compute:
Data undergoes aggregation, cleansing, and manipulation to conform to company standards, including tasks such as format conversion, data compression, and partitioning. This phase employs both batch and stream processing techniques.
Consume:
Processed data is made available for consumption through analytics and visualization tools, operational data stores, decision engines, user-facing applications, dashboards, data science, machine learning services, business intelligence, and self-service analytics.
The efficiency and effectiveness of each phase contribute to the overall success of data-driven operations within an organization.
Source: bytebytego.com
Source: bytebytego.com
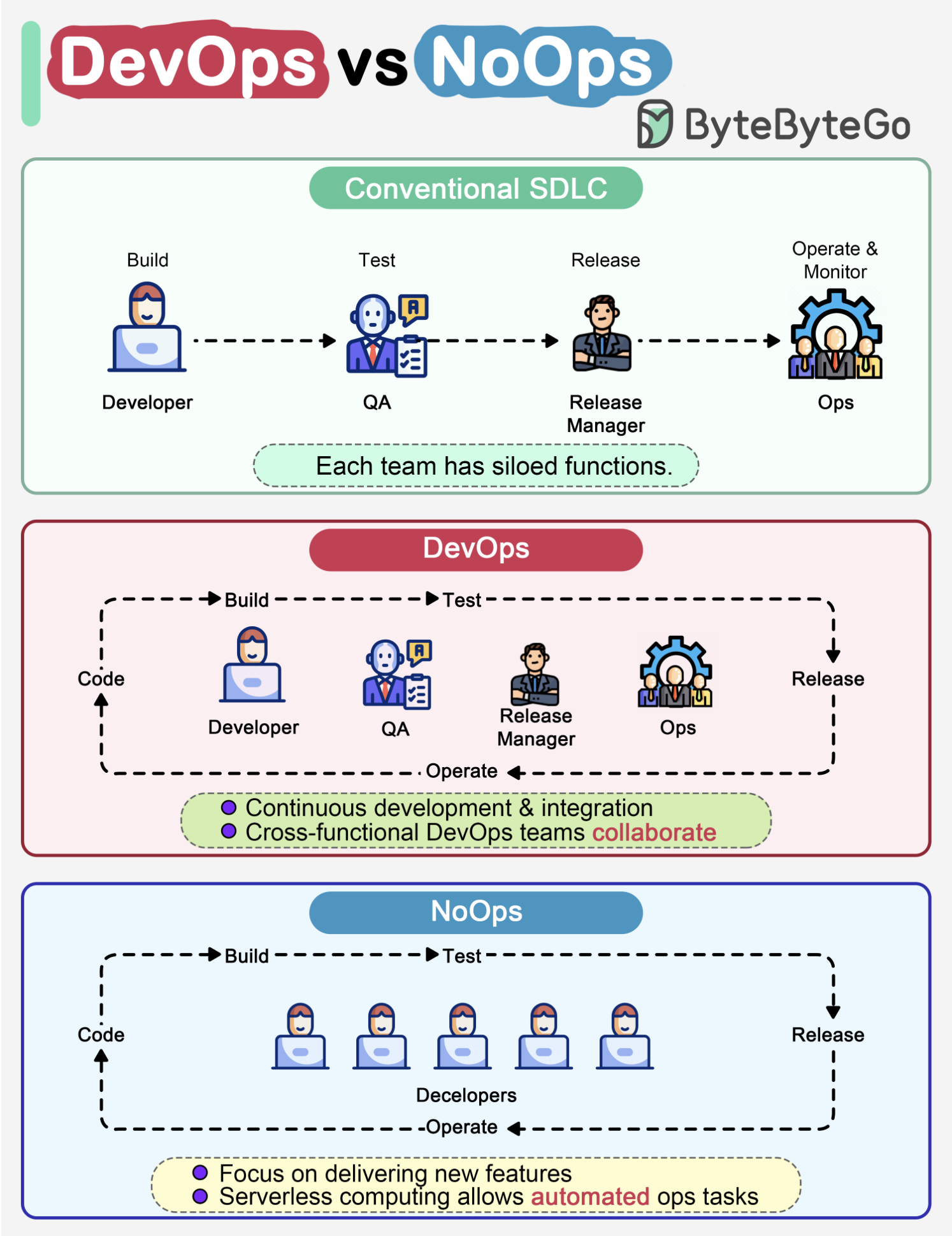
Release Management & Software Development and Lifecycle Management (SDLC)
In a traditional software development, code, build, test, release and monitoring are siloed functions. Each stage works independently and hands over to the next stage.
DevOps, on the other hand, encourages continuous development and collaboration between developers and operations. This shortens the overall life cycle and provides continuous software delivery.
NoOps is a newer concept with the development of serverless computing. Since we can architect the system using FaaS (Function-as-a-Service) and BaaS (Backend-as-a-Service), the cloud service providers can take care of most operations tasks. The developers can focus on feature development and automate operations tasks.
NoOps is a pragmatic and effective methodology for startups or smaller-scale applications, which moves shortens the SDLC even more than DevOps.
Source: bytebytego.com
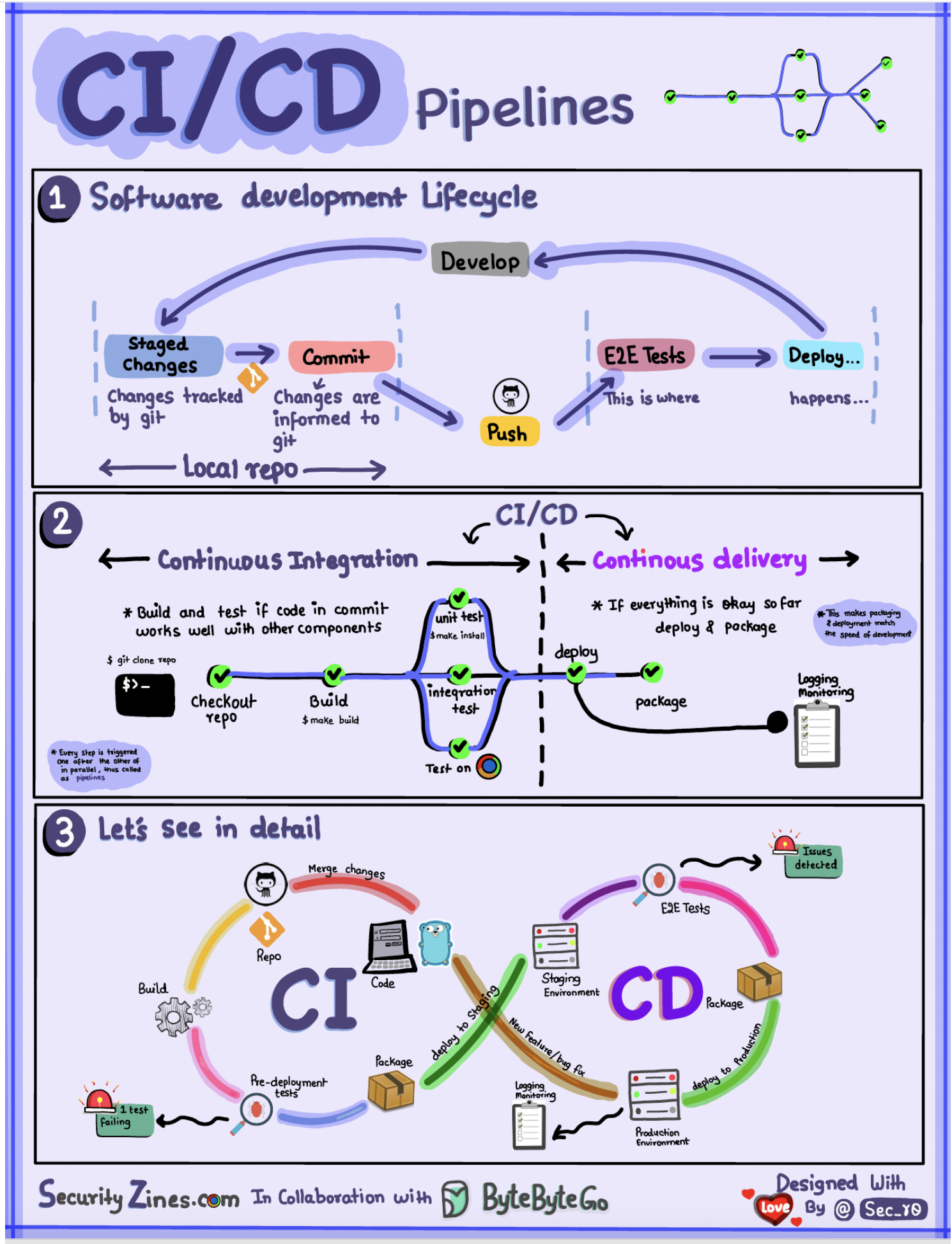
SDLC with CI/CD
The software development life cycle (SDLC) consists of several key stages: development, testing, deployment, and maintenance. CI/CD automates and integrates these stages to enable faster, more reliable releases.
When code is pushed to a git repository, it triggers an automated build and test process. End-to-end (e2e) test cases are run to validate the code. If tests pass, the code can be automatically deployed to staging/production. If issues are found, the code is sent back to development for bug fixing. This automation provides fast feedback to developers and reduces risk of bugs in production.
Difference between CI and CD
Continuous Integration (CI) automates the build, test, and merge process. It runs tests whenever code is committed to detect integration issues early. This encourages frequent code commits and rapid feedback.
Continuous Delivery (CD) automates release processes like infrastructure changes and deployment. It ensures software can be released reliably at any time through automated workflows. CD may also automate the manual testing and approval steps required before production deployment.
CI/CD Pipeline
A typical CI/CD pipeline has several connected stages:
Developer commits code changes to source control
CI server detects changes and triggers build
Code is compiled, tested (unit, integration tests)
Test results reported to developer
On success, artifacts are deployed to staging environments
Further testing may be done on staging before release
CD system deploys approved changes to production
Source: bytebytego.com
FAQ's
What is a Velocity Audit℠?
A Velocity Audit℠ is a focused, data-informed assessment of your delivery system — how work moves from idea to release. It reveals where friction, waste, or misalignment are slowing your growth.
During the audit, I review your release cadence, workflow, team structure, and key metrics such as lead time, change failure rate, and deployment frequency. Together, we’ll identify what’s working, what’s blocking progress, and what small structural changes would create the biggest performance gains.
You’ll walk away with a clear picture of your current delivery health, a prioritized improvement plan, and a roadmap to make releases predictable and scalable.
The Velocity Audit℠ (Lite) is the first step in implementing the SaaS-IDM℠ on your own.
How do I know if SaaS-IDM℠ is right for my business?
SaaS-IDM℠ is built for growing SaaS companies that have traction but are feeling the strain of scale.
It’s right for you if:
→ Releases are inconsistent or stressful
→ Your roadmap slips even though your team is talented
→ Communication between engineering, product, and leadership breaks down under pressure
→ Investors are asking for predictability you can’t provide or prove yet
If you’re at the Seed, Series A, or Series B stage and want delivery to become a strategic advantage — not a bottleneck — SaaS-IDM℠ will fit. The model brings the structure, rhythm, and visibility you need to ship reliably and scale confidently.
The simplest test: if delivery is starting to limit growth, you’re ready for SaaS-IDM℠.
What results can I expect from the SaaS-IDM℠ solution?
You can expect measurable gains in delivery speed and reliability along with increased confidence from your team and your investors.
Within the first 6–10 weeks, most clients see releases become more predictable, communication improves across functions, and delivery friction drops sharply. Over the following months, those improvements compound into faster cycle times, fewer defects, and clearer visibility for leadership and stakeholders.
The outcome isn’t just better releases — it’s a scalable delivery rhythm that restores trust, boosts morale, and gives your company the freedom to focus on innovation and growth.
Will I receive ongoing support after implementing the solutions?
Yes. Every engagement includes an immersive transition phase to ensure your team can sustain the improvements independently. Ongoing support options are available.
Many clients choose to continue with a lightweight oversight partnership, where I monitor delivery performance, refine processes, and advise leadership as new challenges emerge. This ensures your release system continues to evolve as the company scales — without adding internal overhead.
The goal isn’t dependency; it’s stability. Your satisfaction is my top priority. You’ll always have access to clear structure, a measurable rhythm, and expertise when you need it.
How long does it take to see results?
You will experience meaningful impact within 3 weeks and measurable performance gains inside 30 days.
SaaS-IDM℠ doesn’t depend on massive overhauls — it builds from small, incremental momentum that scales fast. I've been doing this work for over 10 years and genuinely love experiencing new and difficult challenges because I know what is on the other side and how to get you there.
Will this work if my team already uses Agile or DevOps?
Yes. SaaS-IDM℠ isn’t another framework to replace what you have; it’s a model that helps your current practices actually work.
Most teams already have the tools — standups, sprints, pipelines — but they’re often disconnected or overloaded (the teams & the tools). The Integrated Delivery Model℠ puts all the pieces together into a predictable delivery rhythm that restores flow without adding ceremony.
If your team is already Agile, SaaS-IDM℠ will take it beyond theory and make it effective. If your DevOps pipeline exists, SaaS-IDM℠ will make it reliable. It’s all about awareness and alignment, not reinvention.
Why can’t I just use AI to do what you do?
SaaS-IDM℠ and AI aren’t competitors — you should be using both!
AI can detect bottlenecks, but it can’t persuade a team to change a behavior, negotiate scope with investors, or rebuild confidence after a series of failed releases. AI can automate parts of delivery, but it can’t create the trust, alignment, or accountability that make integrated delivery work.
SaaS-IDM℠ leverages automation where it makes sense — release pipelines, testing, reporting — yet the real challenge isn’t doing the work, it’s deciding what matters, coordinating people, and establishing rhythm. Those are judgment calls rooted in context, not just data.
You spell Mike with a 'y'; what's up with that?
Yes. Michael was a pretty common name when I was growing up.
In kindergarten, there were 2 other Michaels in my class. Alphabetically, the first one kept Michael and the second accepted Mike. I had been learning simple word combinations, like "My cat." and "My dog." and thought the letter y was fun to write: I wrote My -ke.
My legal name is Michael, spelled the traditional way.
A Seven Stone Pillars, LLC Company

email: [email protected]
© Copyright 2025 Seven Stone Pillars, LLC All rights reserved.